Run Python inside of your Flows
Run Python code directly inside of your Flows and generate outputs.
You can execute Python code inside of a flow by either writing your Python inline or by executing a .py file. You can also get outputs and metrics from your Python code too.
In this example, the flow will install the required pip packages, make an API request to fetch data and use the Python Kestra library to generate outputs and metrics using this data.
Managing Dependencies
Managing Python Dependencies can be frustrating. There’s 3 ways you can manage your dependencies in Kestra:
- Install with pip using
beforeCommands - Set Container Image with Docker Task Runner
- Build Docker Image and set it with Docker Task Runner
For more information, check out the dedicated guide here.
Script Task
If you want to write a short amount of Python to perform a task, you can use the io.kestra.plugin.scripts.python.Script type to write it directly inside of your flow configuration. This allows you to keep everything in one place.
id: python_scriptsnamespace: company.team
description: This flow will install the pip package in a Docker container, and use kestra's Python library to generate outputs (number of downloads of the Kestra Docker image) and metrics (duration of the script).
tasks: - id: outputs_metrics type: io.kestra.plugin.scripts.python.Script beforeCommands: - pip install requests taskRunner: type: io.kestra.plugin.scripts.runner.docker.Docker containerImage: python:slim script: | import requests
def get_docker_image_downloads(image_name: str = "kestra/kestra"): """Queries the Docker Hub API to get the number of downloads for a specific Docker image.""" url = f"https://hub.docker.com/v2/repositories/{image_name}/" response = requests.get(url) data = response.json()
downloads = data.get('pull_count', 'Not available') return downloads
downloads = get_docker_image_downloads()You can also include expressions directly inside of your Python code too. In this example, an input is used inside of the Python method:
id: python_scripts_expression_inputnamespace: company.team
description: This flow will install the pip package in a Docker container, and use kestra's Python library to generate outputs (number of downloads of the Kestra Docker image) and metrics (duration of the script).
inputs: - id: image_name type: STRING defaults: kestra/kestra
tasks: - id: outputs_metrics type: io.kestra.plugin.scripts.python.Script beforeCommands: - pip install requests taskRunner: type: io.kestra.plugin.scripts.runner.docker.Docker containerImage: python:slim script: | import requests
def get_docker_image_downloads(): """Queries the Docker Hub API to get the number of downloads for a specific Docker image.""" url = f"https://hub.docker.com/v2/repositories/{{ inputs.image_name }}/" response = requests.get(url) data = response.json()
downloads = data.get('pull_count', 'Not available') return downloads
downloads = get_docker_image_downloads()Commands Task
If you would prefer to put your Python code in a .py file (e.g. your code is much longer or spread across multiple files), you can run the previous example using the io.kestra.plugin.scripts.python.Commands type:
id: python_commandsnamespace: company.team
description: This flow will install the pip package in a Docker container, and use kestra's Python library to generate outputs (number of downloads of the Kestra Docker image) and metrics (duration of the script).
tasks: - id: outputs_metrics type: io.kestra.plugin.scripts.python.Commands namespaceFiles: enabled: true taskRunner: type: io.kestra.plugin.scripts.runner.docker.Docker containerImage: python:slim beforeCommands: - pip install requests commands: - python outputs_metrics.pyYou’ll need to add your Python code using the Editor or sync it using Git so Kestra can see it. You’ll also need to set the enabled flag for the namespaceFiles property to true so Kestra can access the file.
You can read more about the Commands type in the Plugin documentation.
Handling Outputs
If you want to get a variable or file from your Python code, you can use an output.
You’ll need to install the kestra python module in order to pass your variables to Kestra. This Kestra Python client provides functionality to interact with the Kestra server for sending metrics, outputs, and logs and executing/polling flows. For example, The Kestra ION extra (kestra[ion]) provides a method to read files and convert them to a list of dictionaries, which can be easily converted into a dataframe in Python (using any Python library supporting dataframes, e.g., Pandas or Polars).
Check out the README for more details and examples.
pip install kestraVariable Output
You’ll need to use the Kestra class to pass your variables to Kestra as outputs. Using the outputs method, you can pass a dictionary of variables where the key is the name of the output you’ll reference in Kestra.
Using the same example as above, we can pass the number of downloads as an output.
from kestra import Kestraimport requests
def get_docker_image_downloads(image_name: str = "kestra/kestra"): """Queries the Docker Hub API to get the number of downloads for a specific Docker image.""" url = f"https://hub.docker.com/v2/repositories/{image_name}/" response = requests.get(url) data = response.json()
downloads = data.get('pull_count', 'Not available') return downloads
downloads = get_docker_image_downloads()
outputs = { 'downloads': downloads}
Kestra.outputs(outputs)Once your Python file has executed, you’ll be able to access the outputs in later tasks as seen below:
id: python_outputsnamespace: company.team
tasks: - id: outputs_metrics type: io.kestra.plugin.scripts.python.Commands namespaceFiles: enabled: true taskRunner: type: io.kestra.plugin.scripts.runner.docker.Docker containerImage: python:slim beforeCommands: - pip install requests kestra commands: - python outputs_metrics.py
- id: log_downloads type: io.kestra.plugin.core.log.Log message: "Number of downloads: {{ outputs.outputs_metrics.vars.downloads }}"This example works for both io.kestra.plugin.scripts.python.Script and io.kestra.plugin.scripts.python.Commands.
File Output
Inside of your Python code, write a file to the system. You’ll need to add the outputFiles property to your flow and list the file you’re trying to access. In this case, we want to access downloads.txt. More information on the formats you can use for this property can be found in Script Output Metrics.
The example below write a .txt file containing the number of downloads, similar the output we used earlier. We can then read the content of the file using the syntax {{ outputs.{task_id}.outputFiles['{filename}'] }}
id: python_output_filesnamespace: company.team
tasks: - id: outputs_metrics type: io.kestra.plugin.scripts.python.Script beforeCommands: - pip install requests taskRunner: type: io.kestra.plugin.scripts.runner.docker.Docker containerImage: python:slim outputFiles: - downloads.txt script: | import requests
def get_docker_image_downloads(image_name: str = "kestra/kestra"): """Queries the Docker Hub API to get the number of downloads for a specific Docker image.""" url = f"https://hub.docker.com/v2/repositories/{image_name}/" response = requests.get(url) data = response.json()
downloads = data.get('pull_count', 'Not available') return downloads
downloads = get_docker_image_downloads()
# Generate a file with the output f = open("downloads.txt", "a") f.write(str(downloads)) f.close()
- id: log_downloads type: io.kestra.plugin.scripts.shell.Commands taskRunner: type: io.kestra.plugin.core.runner.Process commands: - cat {{ outputs.outputs_metrics.outputFiles['downloads.txt'] }}This example works for both io.kestra.plugin.scripts.python.Script and io.kestra.plugin.scripts.python.Commands.
Capture Logs
If your Python code needs to log something to the console, we recommend using the Kestra.logger() method from the Kestra pip package to instantiate a logger object — this logger is configured to correctly capture all Python log levels and send them to the Kestra backend.
id: python_logsnamespace: company.team
tasks: - id: python_logger type: io.kestra.plugin.scripts.python.Script allowFailure: true script: | import time from kestra import Kestra
logger = Kestra.logger()
logger.debug("DEBUG is used for diagnostic info.") time.sleep(0.5)
logger.info("INFO confirms normal operation.") time.sleep(0.5)
logger.warning("WARNING signals something unexpected.") time.sleep(0.5)
logger.error("ERROR indicates a serious issue.") time.sleep(0.5)
logger.critical("CRITICAL means a severe failure.")When we execute the above example, we can see Kestra correctly captures the log levels in the Logs view:
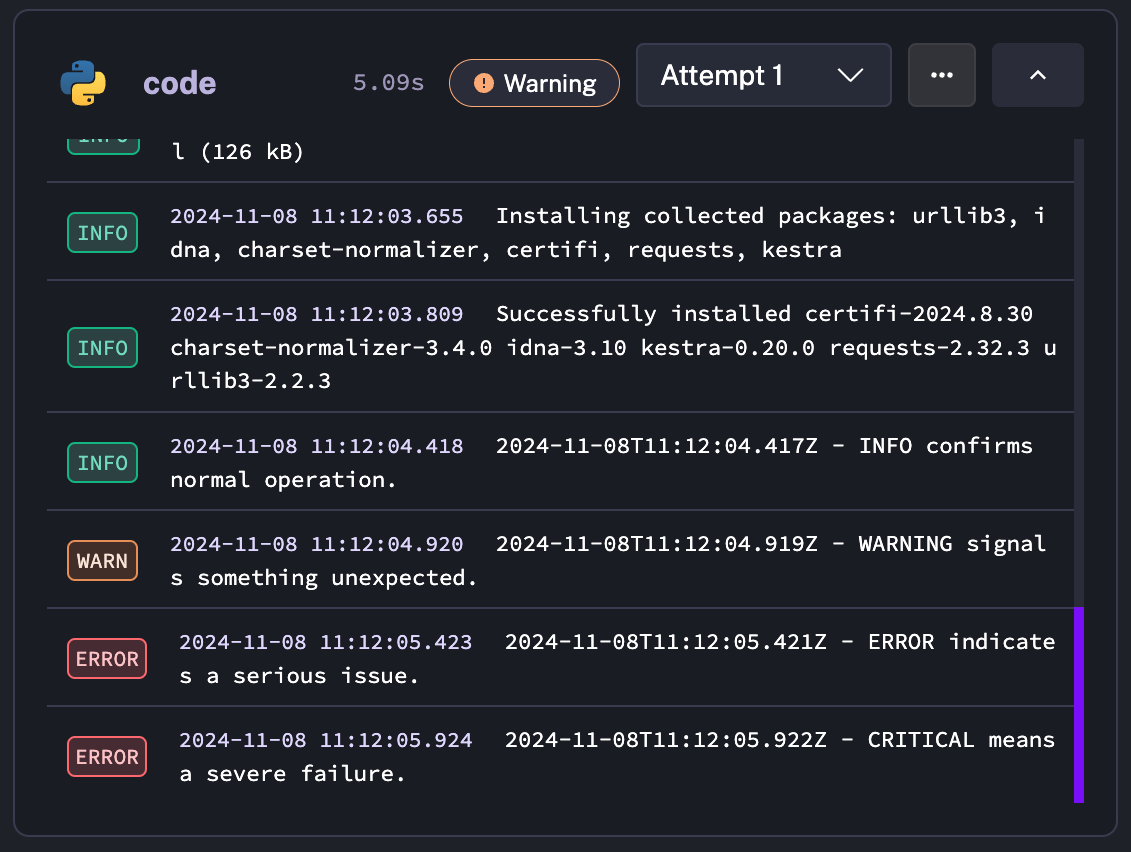
You can read more about the Python Script task in the Plugin documentation
Handling Metrics
You can also get metrics from your Python code. In this example, we can use the time module to time the execution time of the function and then pass this to Kestra so it can be viewed in the Metrics tab. You don’t need to modify your flow in order for this to work.
from kestra import Kestraimport requestsimport time
start = time.perf_counter()
def get_docker_image_downloads(image_name: str = "kestra/kestra"): """Queries the Docker Hub API to get the number of downloads for a specific Docker image.""" url = f"https://hub.docker.com/v2/repositories/{image_name}/" response = requests.get(url) data = response.json()
downloads = data.get('pull_count', 'Not available') return downloads
downloads = get_docker_image_downloads()end = time.perf_counter()outputs = { 'downloads': downloads}
Kestra.outputs(outputs)Kestra.timer('duration', end - start)Once this has executed, duration will be viewable under Metrics.
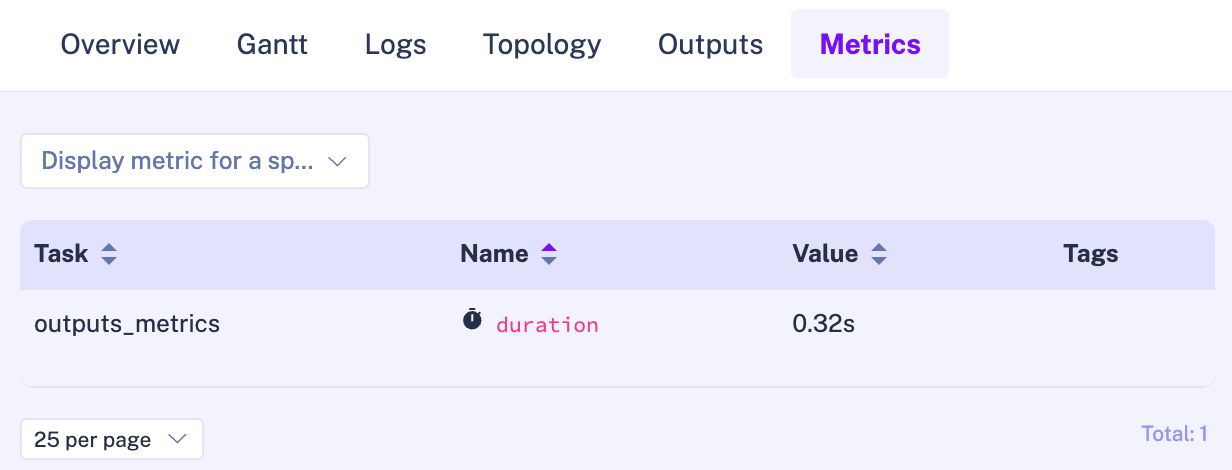
Execute Flows in Python
Inside of your Python code, you can execute flows. This is useful if you want to manage your orchestration directly in Python rather than using the Kestra flow editor. However, we recommend using Subflows to execute flows from other flows for a more integrated experience.
You can trigger a flow execution by calling the execute() method. Here is an example for the same python_scripts flow in the namespace example as above:
from kestra import Flow
os.environ["KESTRA_HOSTNAME"] = "http://host.docker.internal:8080" # Set this when executing this Python code inside Kestra
flow = Flow()flow.execute('example', 'python_scripts', {'greeting': 'hello from Python'})Read more about it on the execution page.
Automate Python with Triggers
You can combine your Python code with a trigger to automatically execute your code. There’s a few key ways you can automate it:
- Run on a schedule
- Run when a webhook is called
- Run when a file is available in a data lake or storage bucket
Run on a schedule
You can use the Schedule Trigger to run your flow on a routine. You can pass the date that the trigger executed to your code through an expression. This is useful when using backfills as it allows you to pass the date of when the execution was suppose to run from the schedule directly to your code, rather than the current time, for example useful when fetching a daily report from a specific date in the past:
id: schedule_codenamespace: company.team
tasks: - id: python type: io.kestra.plugin.scripts.python.Script outputFiles: - "*.txt" script: | date = f"{{ trigger.date | date("yyyy-MM-dd") }}" report_content = f"Daily Report - {date}\nSales: $5000\nUsers: 200"
with open(f"daily_report_{date}.txt", "w") as file: file.write(report_content)
triggers: - id: schedule type: io.kestra.plugin.core.trigger.Schedule cron: "0 8 * * *"Run when a webhook is called
You can use the Webhook Trigger to run your flow when a webhook is called. You can also call the webhook with a body, which can be passed to your code through an expression or environment variable:
id: python_webhooknamespace: company.team
tasks: - id: python type: io.kestra.plugin.scripts.python.Script script: |
response = {{ trigger.body ?? '' }}
print(f"{response['first_name']} {response['last_name']}")
triggers: - id: webhook type: io.kestra.plugin.core.trigger.Webhook key: abcdefgRun when a file is available in a data lake or storage bucket
You can use a Polling Trigger, such as the S3 Trigger to run your flow when a new file arrives in an S3 bucket. This is useful if you have a data pipeline that can start once the data is available and begin transforming it with Python:
id: s3_triggernamespace: company.team
tasks: - id: process_data type: io.kestra.plugin.scripts.python.Script containerImage: ghcr.io/kestra-io/pydata:latest inputFiles: input.csv: "{{ read(trigger.objects[0].uri) }}" outputFiles: - data.csv script: | import os import pandas as pd from kestra import Kestra
df = pd.read_csv('input.csv') df['discounted_total'] = df['total'] * 0.9 df.to_csv('data.csv')
triggers: - id: watch type: io.kestra.plugin.aws.s3.Trigger interval: "PT1S" accessKeyId: "{{ secret('AWS_ACCESS_KEY_ID') }}" secretKeyId: "{{ secret('AWS_SECRET_KEY_ID') }}" region: "eu-west-2" bucket: "kestra-python-s3" action: DELETE filter: FILES maxKeys: 1Execute GraalVM Task
Kestra also supports GraalVM integration, allowing you to execute Python code directly on the JVM, with the potential for performance improvements. There are currently two tasks:
In this example, the Eval task is used to manipulate data from a previous task. GraalVM makes it easy to generate outputs from variables in Python using the outputs property. This is useful if you want to manipulate data and pass the new format to another task.
id: parse_json_datanamespace: company.team
tasks: - id: download type: io.kestra.plugin.core.http.Download uri: http://xkcd.com/info.0.json
- id: graal type: io.kestra.plugin.graalvm.python.Eval outputs: - data script: | data = {{ read(outputs.download.uri) }} data["next_month"] = int(data["month"]) + 1